
Reinforcement Learning 101
Introduction
Reinforcement learning is a framework for learning how to interact with the environment from experience.
- Steve Brunton, University of Washington
Reinforcement learning (a.k.a RL) is a machine learning paradigm where an agent (AI) learns to interact with an environment to achieve a goal. The agent learns through trial and error. It receives feedback in the form of rewards or penalties for its actions. Hence, the agent’s goal is to maximize the total reward it receives over time.
Different from supervised or unsuperivsed learning, our agent receives as input the current state of the environment and outputs an action to take.
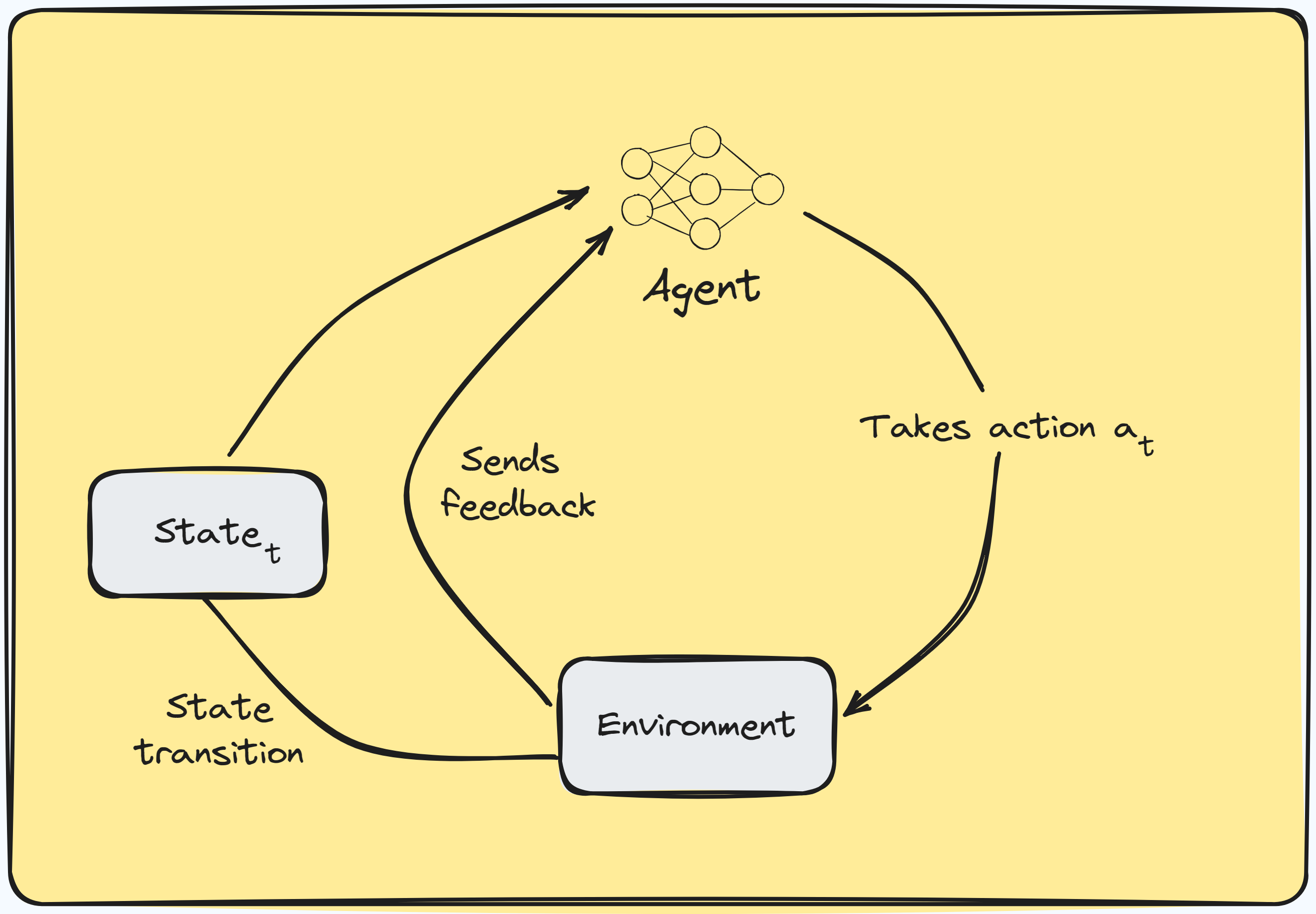
RL terminology
A RL process is often referred to as a Markov Decision Process (MDP). If you are familiar with MDPs or Markov chains, you’d have guessed that the transition from one state to another is memoryless. That is, the next state depends only on the current state.
As a matter of fact, a state in RL is a representation of the environment at a given time. The agent uses this representation to decide which action to take next and the term action space refers to the set of all possible actions the agent can take. For instance, if you are training an agent to play a game like pacman, the action space would be: .
Given that after each taken action the agent receives a reward and it aims to maximize the cumulative reward, this cumulative reward called return can be expressed as:
is a trajectory and is represents a sequence of states, actions and rewards: . We can add a new term to the return called discount rate . The discount rate tells us how much we value future rewards compared to immediate ones. A high discount rate means we value future rewards more than immediate ones. Taking into account we can rewrite the return as:
Tasks in reinforcement learning
An instance of a reinforcement learning problem is called a task. A task can be episodic or continuing. In episodic tasks, there is a starting state and a terminal states. Thus, there’s a trajectory where is a terminal state. Think of a level in Super Mario Bros for instance, the level starts when Mario is at the beginning of the level and ends when he reaches the flag. In continuing tasks, there are no terminal states. The agent keeps interacting with the environment indefinitely (automated stock trading).
Decision making with a policy
A policy is a function that maps states to actions. It tells the agent what action to take in a given state. You can think of it as a heuristic or a strategy. It’s a learnable function and the goal of is to find the optimal policy that maximizes the expected return. Policy based methods define a function that can be learned directly. There are two types of policy based methods:
- Deterministic policy: . This policy will always output the same action for a given state.
- Stochastic policy: . This policy outputs a probability distribution over the action space for a given state.
When training an agent, we often use a value function to evaluate how good a state or action is. The value function is a function that maps a state to the expected value of being at that state. A state value is the expected discounted return starting from state and following policy .
RL use cases
Most of the time, reinforcement learning is presented in the context of games. However, it has a wide range of applications. Here are a few examples:
- Game playing: AlphaGo
- Robotics: training robots to perform tasks in the real world. You can have a look at LeRobot by 🤗Hugging Face for instance.
- Finance: it can be used for optimization problems in finance
- NLP: modern large language models like Gemini or LLaMA are trained using RLHF .
Conclusion
Reinforcement learning is a powerful framework for learning how to interact with the environment. It’s a trial and error process where the agent learns from its mistakes. This post covered the basics of RL but we can do better with deep reinforcement learning which combines deep learning and RL. Stay tuned for more posts on this topic!